Supabase (Postgres): data mart transakcija nekretnina za Excel i API
Dešava se da podaci o transakcijama već postoje, ali kao dugačka i nepregledna tabela iz koje je teško brzo odgovoriti na osnovna pitanja: kako se cena menja po mesecima, koji projekti rastu, gde su odstupanja i kako uporediti 1BR i 2BR.
U ovom projektu zadatak je bio praktičan: srediti podatke o transakcijama nekretnina u Supabase-u (Postgres) tako da klijent može sam da izvozi gotovu mart tabelu u Excel i koristi filtere bez stalnih zahteva ka developeru.
Šta je trebalo dobiti
- Normalizovati strukturu tabela (projekti, investitori, transakcije) i tipove podataka.
- Povezati projekte i investitore preko ključeva.
- Pripremiti vremensku analitiku (godina/mesec).
- Sastaviti agregate cena po projektima i broju soba.
- Ubrzati izveštajne upite indeksima.
- Izložiti gotove skupove kroz Supabase API (ulaz: p_id/d_id ili "sve").
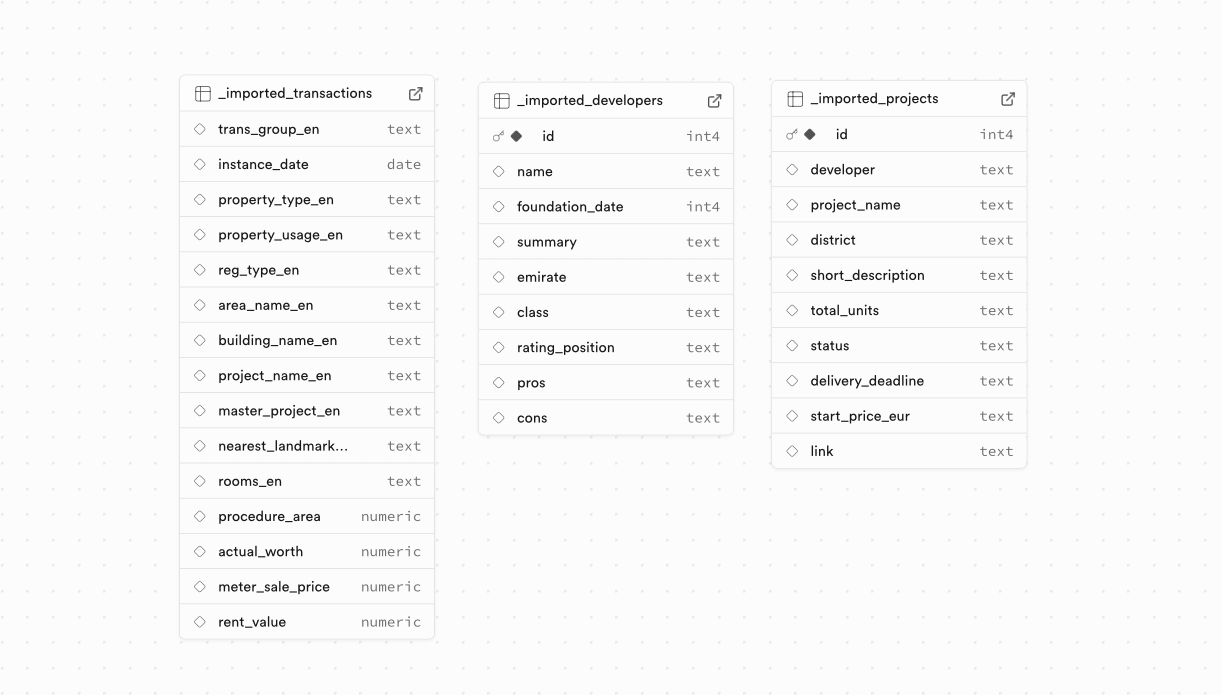
1. Uvoz izvornih podataka
Podaci su učitani u Supabase "kakvi jesu": bez prethodno pripremljene šeme, sa mešovitim tipovima polja i nestabilnim vrednostima (tekstovi, datumi, brojevi, nazivi projekata).
Od klijenta su stigla 2 Excel fajla i 1 CSV fajl veličine 150 MB od ~900.000 redova.
To je omogućilo brz početak rada sa realnim podacima i identifikaciju problema kvaliteta i strukture na živom obimu.
2. Pažljiva normalizacija i sređivanje šeme
Zatim je usledio pažljiv rad na dovođenju baze u stabilno stanje:
- izdvajanje referentnih entiteta (projekti, investitori) u zasebne tabele,
- postavljanje veza između entiteta preko ključeva,
- usklađivanje tipova kolona (date, numeric umesto text),
- dodavanje indeksa za realne izveštajne upite,
- obogaćivanje podataka (na primer, normalizacija room/bedroom vrednosti iz teksta u numerička polja),
- dodavanje posebnih polja p_year i p_month za vremensku analitiku.
Godina i mesec su izdvojeni u posebna polja da se izbegne EXTRACT(YEAR/MONTH) u svakom upitu i pojednostave grupisanje i sortiranje pri izvozu u Excel.
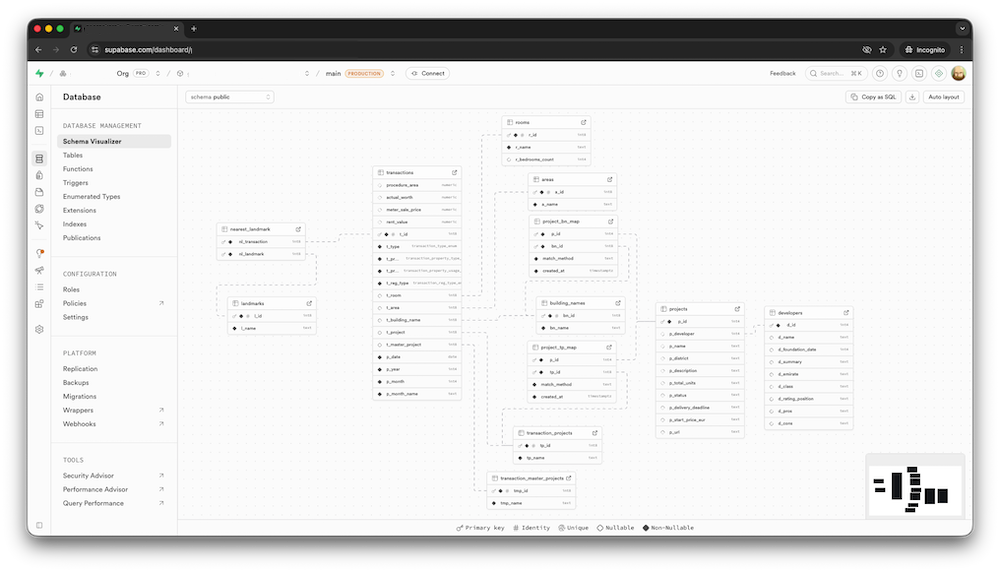
3. Priprema baze za spoljašnji API
Struktura i upiti su dovedeni u oblik pogodan za spoljašnju potrošnju: ravni skupovi podataka, stabilna polja, predvidivi filteri po ključevima (p_id, d_id, godina, mesec). Sam spoljašnji API nije bio deo ovog zadatka, ali su baza i data mart slojevi pripremljeni za to.
Rezultat
- Posle raw importa podaci su zauzimali oko 300 MB u Supabase-u; nakon normalizacije i dodavanja novih indeksa, veličina je smanjena na 237 MB.
- I sa novim indeksima, baza je ostala u okvirima Supabase Free Tier limita.
- Analitički upiti su postali primetno brži zahvaljujući indeksima i predizračunatim vremenskim poljima.
- Baza je postala spremna za skaliranje: izveštaji, spoljašnji API i BI alati.
Kome ovo odgovara
- Ako podaci već postoje, ali su teški za korišćenje bez ručnog čišćenja.
- Ako je potrebna vremenska analitika (mesec/godina) i poređenja po kategorijama.
- Ako rezultat treba da bude poslovno upotrebljiv: Excel/BI + API, a ne samo SQL.
Ako vam treba sličan rezultat: sređujem tabele, projektujem šemu za analitiku, gradim data mart slojeve i pripremam pristup kroz API.
Tehnički detalji: kako da učitate veliki lokalni CSV u Supabase
Ispod je praktičan scenario kada je CSV fajl veliki i nalazi se lokalno na vašem računaru.
1) Uzmite IPv4 connection string u Supabase-u
- Otvorite projekat u Supabase-u: Project Settings -> Database -> Connection string.
- Izaberite režim URI i opciju IPv4 (Direct connection).
- Kopirajte string ovog oblika:
postgresql://postgres.<project-ref>:<password>@<host>:5432/postgres?sslmode=require2) Pokrenite Docker container sa Postgres klijentom i mapirajte folder sa CSV fajlom
docker run --rm -it \
-v "$(pwd)":/work \
postgres:16 \
psql "postgresql://postgres.<project-ref>:<password>@<host>:5432/postgres?sslmode=require"Ovo je jedna komanda: odmah otvara psql, a trenutni folder iz terminala mapira se u container kao /work.
3) Kreirajte tabelu u Supabase-u (pre importa)
Pre importa samo kreirajte potrebnu tabelu u Supabase-u (kroz SQL Editor ili unapred u istom psql).
4) Uvezite CSV u tabelu
Već ste unutar Docker-a i povezani na bazu u psql, pa komandu pokrećete direktno:
\copy import.deals_raw
from '/work/deals.csv'
with (format csv, header true, delimiter ',', quote '"', null '');null '' znači: prazne vrednosti u CSV-u učitaće se kao NULL. Ako je u fajlu NULL obeležen tekstom NULL, koristite null 'NULL'.
5) Brza provera
select count(*) as rows_loaded from import.deals_raw;
select * from import.deals_raw limit 5;Ako je fajl veoma veliki, učitavajte ga u batch-evima (po delovima), a indekse dodajte nakon importa - tako je obično brže i stabilnije.