Lokalni automatizovani prevod sa engleskog na ruski uz model Qwen 2.5 32B
Cilj ovog testa je bio praktičan: proveriti da li je moguć potpuno automatizovan prevod sa engleskog na ruski lokalnim modelom, bez oslanjanja na plaćene API-je za glavni obim.
Kao baza je korišćen Qwen 2.5 32B. Zadatak nije bio samo „dobiti prevod“, već napraviti radni proces za realne obime: predvidiva brzina, kontrola kvaliteta i jasna ekonomika.
Ova faza direktno nastavlja OCR fazu: OCR je dao izvorni LaTeX iz PDF-a, a ovde je urađen automatizovani prevod i doterivanje kvaliteta. Kontekst i primer neprevedenog bloka su u DeepSeek OCR 2 postu.
Šta je bilo važno za biznis
- Automatski prevesti velike EN obime u RU, bez ručnog rada po pasusima.
- Smanjiti trošak u odnosu na pristup „100% preko plaćenog API-ja“.
- Zadržati kvalitet pogodan za objavu i dalju upotrebu.
- Automatski prepoznati loše segmente i odvojeno obraditi samo problematični deo.
Ključna ideja: lokalni prevod za stabilnu većinu, a mali teži deo preusmeriti na jači (skuplji) fallback kanal.
Ako imate sličan zadatak (masovni prevod dokumentacije, baze znanja, kataloga, sadržaja sajta) i želite niži trošak bez pada kvaliteta, detalje možete poslati kroz brif.
Rezultat
- Potpuno automatizovan tok je implementiran i pokrenut lokalno na Mac-u.
- Na CPU je scenario bio nepraktičan za radne obime zbog velike latencije.
- Na GPU je dobijena brzina pogodna za praktičan rad.
- Oko 95% segmenata prevedeno je automatski bez intervencije.
- Oko 5% je imalo artefakte: CJK simbole, neprevedene delove ili suvišne komentare u izlazu.
Tih 5% može automatski da se detektuje i pošalje u poseban tok dorade.
Ekonomika
Ako se sve prevodi preko plaćenog API-ja, trošak raste linearno sa obimom. U lokalnom pristupu glavni trošak je podešavanje i lokalna obrada, a varijabilni trošak po narednom prolazu je niži.
U praksi je to dalo radni model:
- glavni obim se prevodi lokalno (jeftinije);
- samo problematičnih 5% ide u plaćeni API (skuplje po tokenu, ali mali obim);
- ukupan trošak je znatno niži nego kod „100% API“.
Kako je obrađeno problematičnih 5%
Problematični segmenti su automatski označavani za ponovni prevod:
- detekcija neočekivanih skripti/simbola (npr. CJK simboli u RU izlazu);
- provera curenja izvornog jezika (veći EN fragmenti u RU rezultatu);
- meta/komentarski artefakti koji ne smeju u finalni sadržaj.
Taj mali podskup se zatim može poslati u OpenAI API kao drugi korak: skuplje po segmentu, ali kvalitetnije tamo gde je lokalni izlaz nestabilan. Tako se dobija kontrolisan hibridni pipeline: brzo, prosečno jeftinije i kvalitetan finalni rezultat.
Tehnički detalji
Ispod je PoC konfiguracija koja je postala radni baseline na Mac-u.
Cilj i ograničenja PoC-a
- Prevesti LaTeX dokument sa mnogo naslova, pasusa i posebno fusnota, uz visoku pravno-semantičku tačnost.
- Raditi lokalno na macOS bez direktne instalacije alata na sistem.
Finalni profil modela
Ciljni profil kvaliteta za ovaj PoC bio je Qwen2.5-32B-Instruct, kvantizacija Q4_K_M.
Link modela: Qwen/Qwen2.5-32B-Instruct-GGUF.
Radna LM Studio konfiguracija na ovom hardveru: GPU offload max (UI je prikazivao 64/64), početni kontekst 4096.
Testiran je i Q3_K_M: bio je brži, ali slabiji u pravnoj preciznosti formulacija i stabilnosti terminologije. Finalni kvalitet baseline je ostao Q4_K_M.
Kako je tok prevoda organizovan
- Izvor se deli na blokove po praznim redovima.
- Dugi blokovi se dele prioritetno po rečenicama (
. ? !), uz bezbedan fallback po razmaku/limitu. - Koristi se jedan strogi system prompt (bez posebnih review/retry/heading režima).
\footnote{...}i linkovi (\url,\href,\hyperref,\nolinkurl,\path) se ne prevode.
Validacija i auto-kontrola kvaliteta
- Meta-komentari se odbacuju (
Note,Correction,Finalitd.). - Markdown code-fence u izlazu se odbacuje.
- Proverava se curenje engleskih pomorskih termina u RU izlazu.
- Detektuju se CJK simboli, dupli prelomi redova i drugi obrasci „prljavog“ izlaza.
Eksperimenti po modelima
qwen2.5:7b: brži, ali slabiji u terminologiji i stabilnosti na složenim pasusima.qwen2.5:14b: bolji od 7b, ali i dalje sa quality drift-om i mešanjem jezika.qwen2.5:32b: znatno bolji kvalitet, ali mnogo zahtevniji po memoriji i resursima.
Zašto CPU nije bio upotrebljiv, a GPU jeste
- Na CPU-u su dugi segmenti pravili dugačke timeout/retry cikluse, pa je pun prolaz bio nepraktičan.
- Nije bio bitan samo prompt; ključni su bili profil resursa i runtime tuning.
- Na Mac GPU-u sa
Q4_K_Mprofilom brzina je porasla više puta uz prihvatljiv pravni kvalitet.
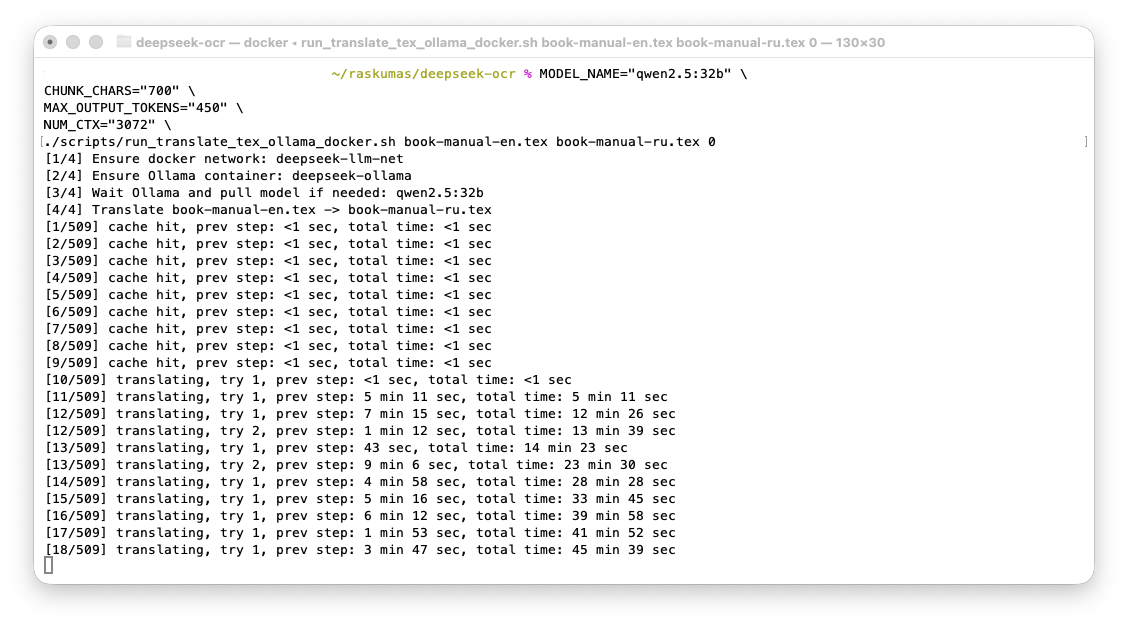
Slika 1. CPU prolaz: jedan pasus je trajao otprilike 5-9 minuta.
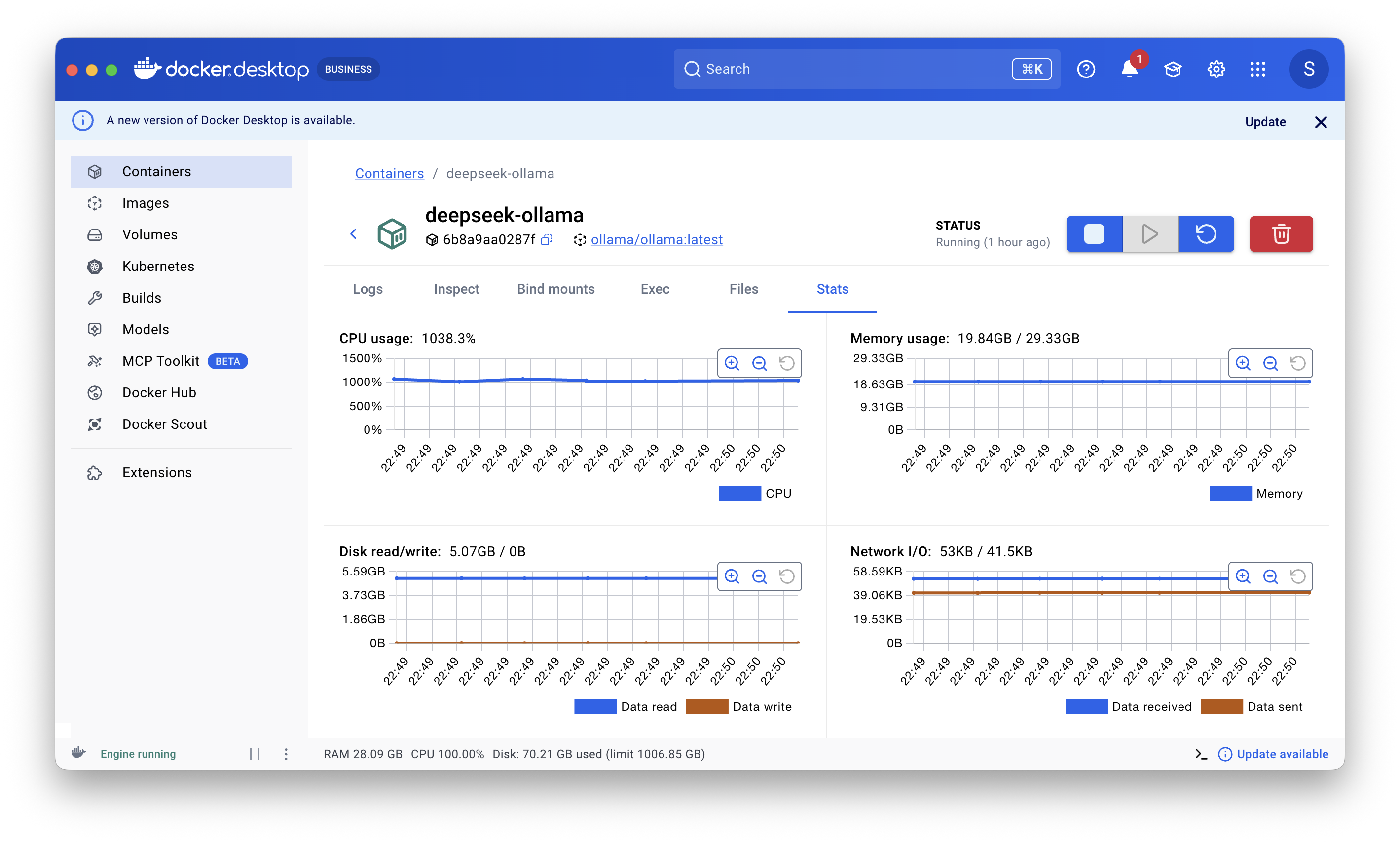
Slika 2. CPU prolaz je rađen kroz Docker; potrošnja memorije je bila oko 20 GB. GPU prolaz je rađen odvojeno u LM Studio.
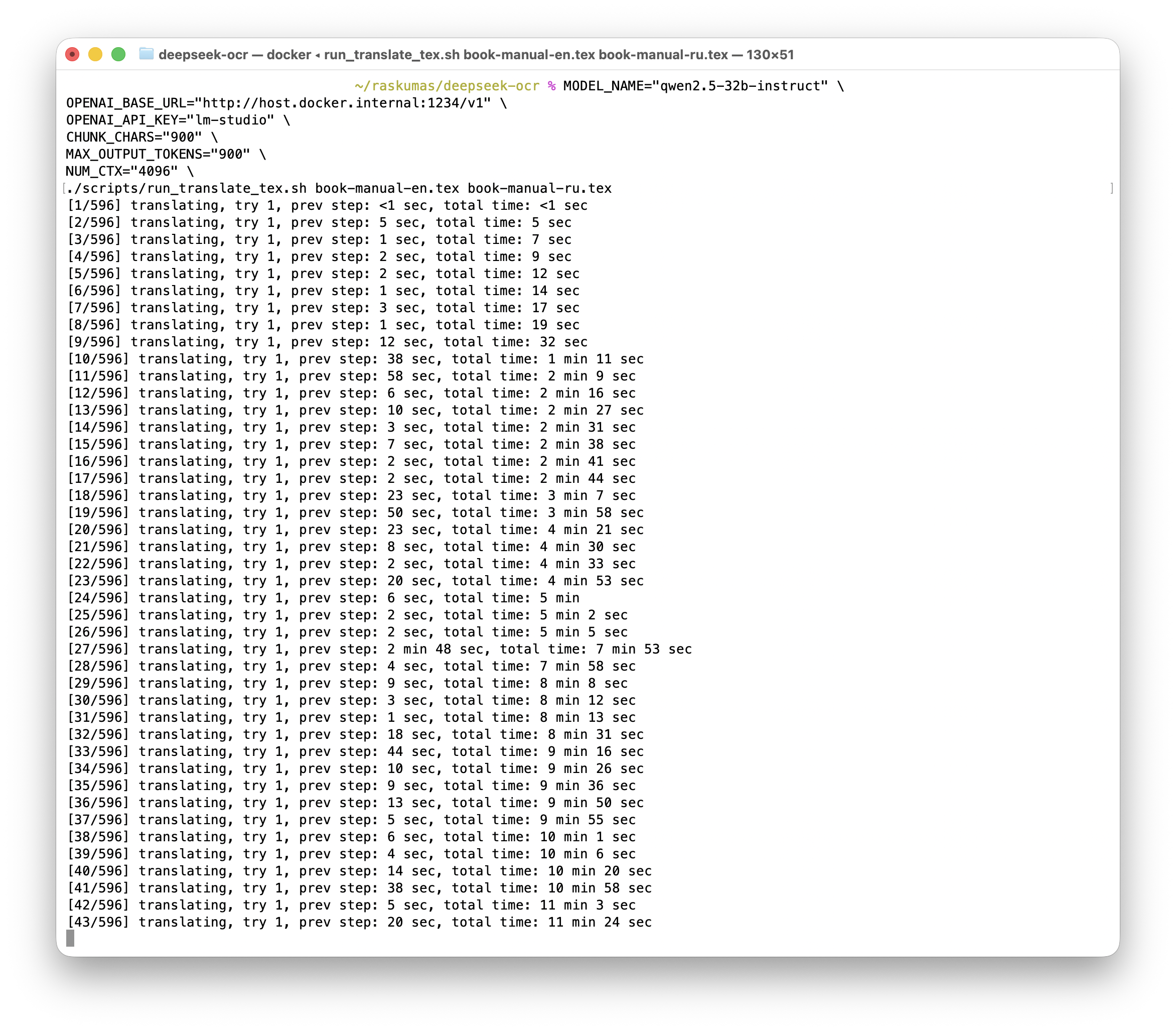
Slika 3. Ubrzani profil: jedan pasus je trajao oko 15 sekundi.
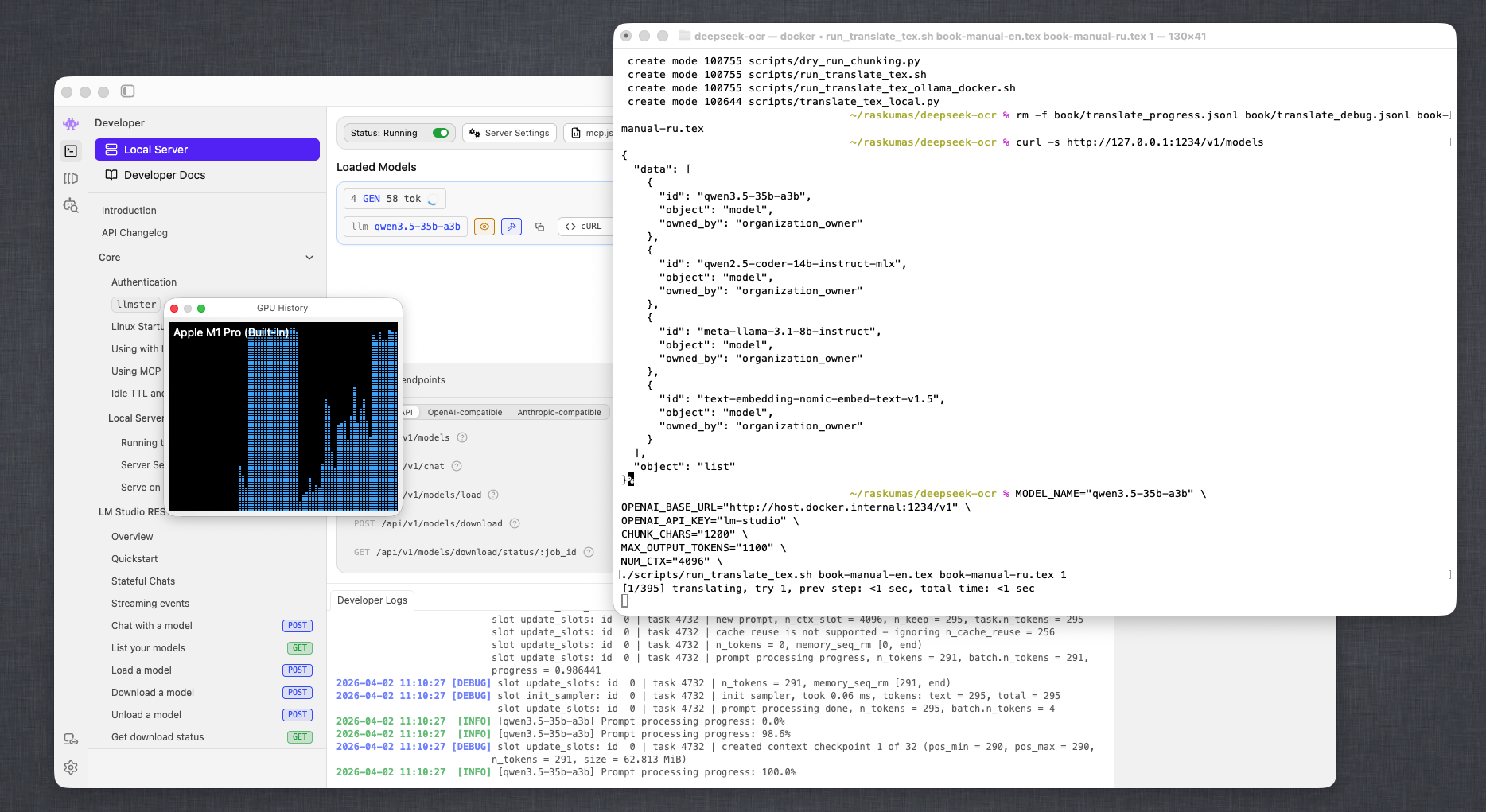
Slika 4. Stabilna GPU iskorišćenost tokom prolaza (LM Studio + macOS System Monitor).
Inference podešavanja i njihov uticaj
Kvalitet na prvih 12 redova je vidljivo porastao zbog kombinacije tri faktora: manje stepena slobode modela (jedan strogi system prompt, bez review/retry/heading režima), čistiji ulaz (samo prevodivi tekst, ne ceo LaTeX markup) i stroga validacija izlaza (meta/šum se odbacuje i radi retry).
Pored izbora modela, snažan uticaj su imali i inference/pipeline parametri:
temperature: glavni regulator varijacije. Niže (oko0.0) daje stabilnije pravne formulacije i manje šuma.top_p: seče „rep“ verovatnoća. Uztemperature=0uticaj je mali; uz veću temperaturu nižitop_pdaje stroži stil, ali može odseći dobre alternative.max_tokens: plafon dužine odgovora. Prenisko vodi ka odsecanju; previsoko ne povećava kvalitet direktno, ali smanjuje rizik od prekida na dugim segmentima.num_ctx: dostupni kontekst. Veći poboljšava koherentnost dugih segmenata, ali diže latenciju/opterećenje.4096je ovde bio dobar balans.CHUNK_CHARS(pipeline parametar): veličina prevodnog segmenta. Veće daje više lokalnog konteksta, ali diže rizik timeout-a/degradacije; manje je stabilnije, ali može smanjiti povezanost između rečenica.
Zaključak: inference i chunking parametri su uticali na rezultat skoro koliko i izbor modela.
Konačna tehnička šema
- Extract text -> translate -> assemble kao bazni tok.
- Izlazni
.texse piše od početka prolaza; ako segment padne, upisuje se fallback i prolaz se ne zaustavlja. - Posle punog pokrivanja, quality-gate detektuje artefakte i pravi poseban red problematičnih segmenata.
- Dorađuju se samo problematični segmenti (jači lokalni model ili plaćeni API), pa se radi finalno sklapanje.
Važno: pokušano je i direktno slanje „sirovog" LaTeX markup-a na prevod, ali je taj režim davao više halucinacija i lomljenja strukture. Radni pristup je bio da se iz LaTeX-a izdvoje samo prevodivi tekstualni delovi, prevedu, pa da se dokument ponovo sastavi uz očuvan markup.
Slika 5. Finalni rezultat: prevedena stranica u Overleaf-u (LaTeX + generisani PDF). Izvorni neprevedeni blok je u OCR postu.
Glavni tehnički zaključak: za ovu klasu dokumenata, najbolji praktični kompromis je lokalni masovni prevod na 32B profilu + automatska detekcija grešaka + ciljano doterivanje malog teškog podskupa.