Paketni prevod 3000 turističkih ruta na ruski preko n8n + OpenAI (uz faznu proveru kvaliteta)
Klijentu je trebalo da prevede veliki sadržajni skup na ruski jezik: oko 3000 redova sa nazivima i opisima turističkih ruta na različitim evropskim jezicima (uglavnom EN/DE/FR, ali bez garancije da su samo oni).
Običan chat nije praktičan za ovakav zadatak: obim je prevelik, potrebna je paketna obrada, očuvanje strukture fajla i predvidiv rezultat kroz ceo dataset. Klijent je odmah isključio Google Translate jer je bio potreban pažljiviji prevod za turističke opise.
Šta je bilo važno za biznis
- Prevesti ceo niz podataka (3000 redova) bez ručnog copy/paste rada po delovima.
- Sačuvati strukturu Excel fajla, uključujući skrivene kolone.
- Uraditi međuproveru kvaliteta pre punog pokretanja.
- Isporučiti rezultat u formatu koji klijent može odmah da importuje dalje.
- Smanjiti potrebu za ručnim doterivanjem nakon automatskog prevoda.
Da bi se smanjio rizik, posao je puštan fazno: prvo testni uzorak, zatim fajl sa 500 redova za međuproveru, i tek nakon potvrde kvaliteta — puni prolaz.
Ako imate sličan zadatak (masovni prevod kataloga, opisa, kartica, ruta ili sadržaja za import), pošaljite fajl i zahteve kroz brif — mogu da složim paketnu obradu i scenario provere kvaliteta za vaš obim.
Šta je urađeno u n8n
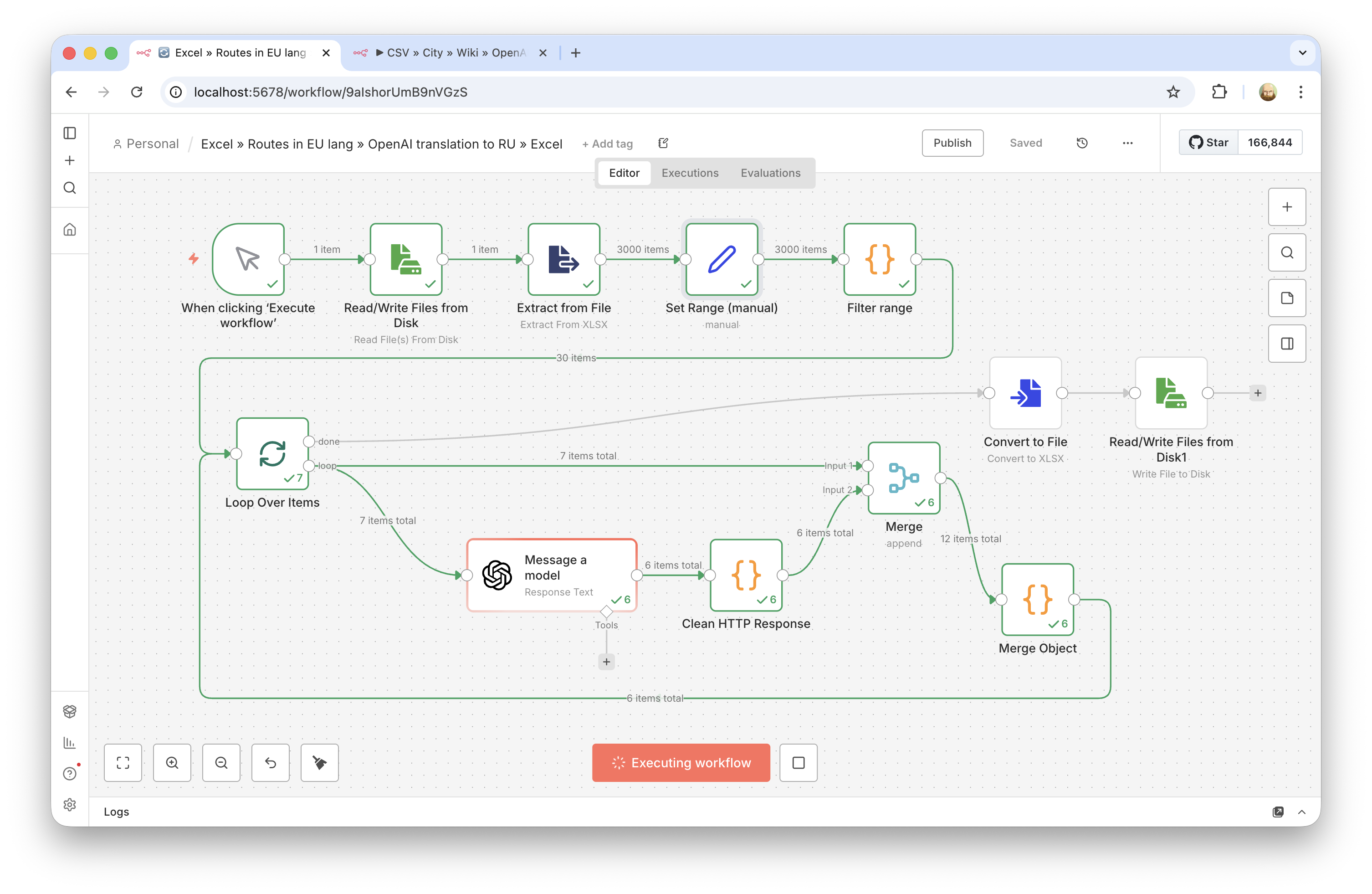
Za ovaj zadatak napravljen je n8n workflow koji obrađuje redove iz tabele paketno, šalje u OpenAI prevod naziva i opisa, dobija striktno strukturisan odgovor i upisuje rezultat nazad u izlazni fajl.
- Napravljen je tok paketne obrade Excel podataka umesto ručnog rada kroz chat.
- Urađen je testni prolaz na malom broju zapisa radi provere kvaliteta prevoda.
- Nakon usaglašavanja kvaliteta — međuprolaz na 500 redova i ručni spot-check.
- Nakon potvrde klijenta — puni prolaz kroz ceo dataset.
- Sačuvan je format isporuke u Excelu (
.xlsx), pogodan za dalji import kod klijenta. - Uvaženo je zahtevano očuvanje strukture tabele (uključujući skrivene kolone).
Tehnički detalji: kako je obrada bila organizovana
Tehnički gledano, zadatak nije bio samo "prevedi tekst", već izgradnja stabilnog pipeline-a za veliki fajl, bez gubljenja strukture podataka i bez nepredvidivog rezultata na 3000 redova.
- Paketna obrada umesto jednog velikog zahteva. Tabela je razbijena na pojedinačne zapise i svaki red prolazi isti scenario prevoda. Tako se uklanja ograničenje običnog chata po obimu i dobija kontrola grešaka po redovima.
- Strukturisan odgovor modela. Za svaki red model vraća JSON sa dva polja (prevod naziva i opisa), tako da rezultat može pouzdano da se mapira nazad u tabelu bez ručnog čišćenja.
- Međuprovere kvaliteta. Umesto puštanja "odmah na sve", uvedeni su kontrolni koraci: prvo desetine redova, zatim 500. To značajno smanjuje rizik masovne greške u promptu ili formatu.
- Očuvanje izvorne strukture fajla. Važan zahtev je bio da se ne pokvari originalni Excel i ne izgube skrivene kolone, pa je rezultat isporučen u istom formatu (
.xlsx), a ne kao "ravna" CSV/Google Sheets obrada. - Formatiranje opisa. Po dogovoru sa klijentom opisi su ostavljeni bez HTML tagova, sa prelomima redova/pasusima u čitljivom obliku, da odgovaraju postojećem formatu podataka.
Tehnički detalji: važan zaključak o promptu (kraće je bilo bolje)
Posebno zanimljiv detalj iz ovog zadatka: prvo je napravljen detaljan prompt sa mnogo ograničenja i pojašnjenja (tip teksta, stil, format, liste, formulacije za nazive ruta itd.). Formalno je delovao "ispravnije", ali se u praksi pokazao previše komplikovanim.
Nakon povratne informacije klijenta prompt je pojednostavljen. Rezultat je postao bolji: prevod je bio bliži očekivanjima klijenta i njegovom već proverenom primeru. Ovo je dobar praktičan primer za LLM automatizacije: dugačak i veoma detaljan prompt ne daje uvek bolji output, naročito kada je cilj neutralan masovni prevod, a ne složena stilizacija.
- Složen prompt je davao više nepotrebne interpretacije i "samostalnosti".
- Jednostavniji prompt je bolje pogodio očekivani ton i format.
- Odluka nije doneta teorijski, već kroz brze testne prolaze i pregled realnih redova.
Praktični zaključak: u n8n pipeline-ima sa LLM-om vredi unapred planirati kratku A/B proveru promptova na realnim podacima pre masovnog pokretanja.
Rezultat
- Preveden je ceo skup od oko 3000 redova (nazivi + opisi ruta).
- Posao je urađen fazno uz međupotvrdu kvaliteta (test -> 500 redova -> pun obim).
- Fajl je isporučen u Excel formatu pogodnom za dalji import kod klijenta.
- Klijent je prihvatio rezultat i potvrdio kvalitet prevoda.
Ovakav format dobro radi za zadatke gde nije potreban "jedan odgovor AI-ja", već kontrolisan masovni prolaz kroz tabelu uz proveru kvaliteta i normalnu isporuku rezultata u radnom formatu.